







At the heart of DataNimbus Designer’s approach are reusable blocks—modular units that encapsulate common data tasks and serve as the fundamental building blocks for your workflows. These standardized, pre-configured components handle specific data operations while maintaining consistent behavior across implementations.
Reusable blocks span the entire data pipeline lifecycle:
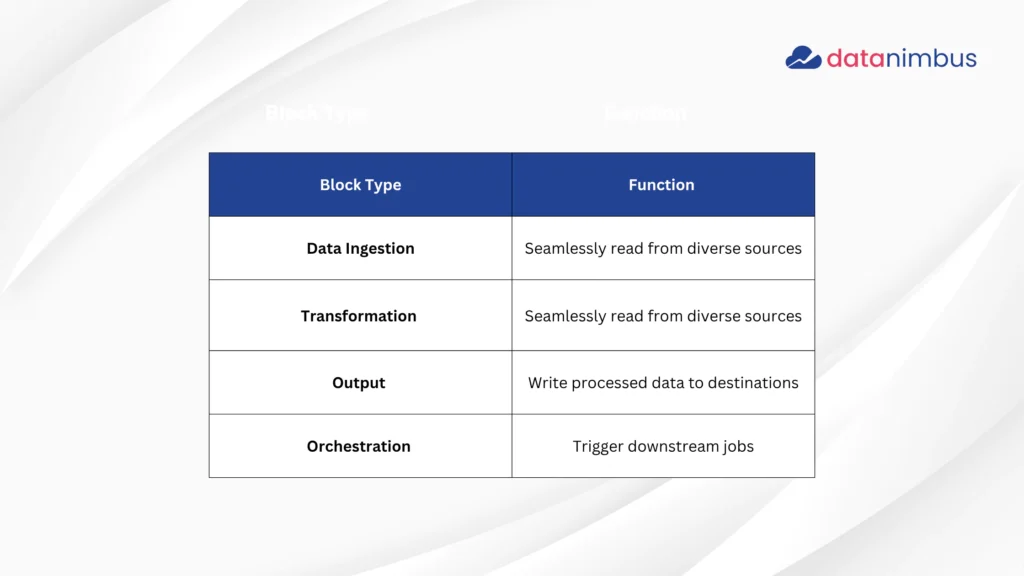
Reusable blocks span the entire data pipeline lifecycle:

This website uses cookies to facilitate and enhance your use of the website and track usage patterns. By continuing to use this website, you agree to our use of cookies as described in our Privacy Policy. ACCEPT